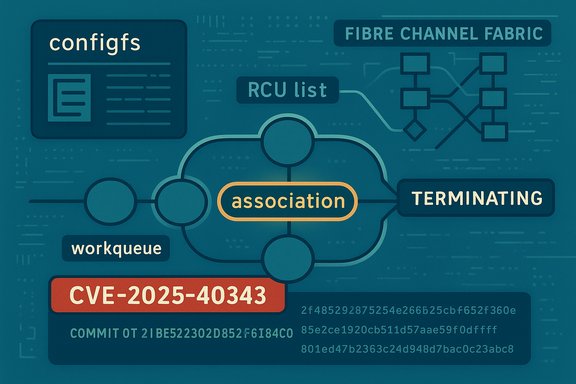
A subtle race in the Linux kernel’s NVMe‑over‑Fibre‑Channel stack was assigned CVE‑2025‑40343 after maintainers fixed a sequencing bug that could let the same association deletion be scheduled twice during a forced port shutdown — a corner case that, in the field, risks freeing resources twice and producing kernel instability on systems using nvmet‑fc.
Background / Overview
NVMe over Fibre Channel (nvmet‑fc) exposes NVMe target semantics over an FC transport and must carefully coordinate asynchronous events: controller/association teardown, transport notifications, and deferred cleanup work executed on kernel workqueues. When administrators force a port shutdown through the configfs control interface, multiple nvmet‑fc code paths can race to schedule cleanup for the same association. The upstream fix for CVE‑2025‑40343 prevents the same association deletion work from being queued twice by ensuring a deletion-in-progress flag is used to guard scheduling, closing the race window introduced by current scheduling ordering. This is not a purely academic defect. On production hosts that use NVMe‑FC — storage servers, hypervisors attaching SANs, and host systems for scale-out storage — the observable consequences are availability impacts: kernel WARNs, list corruption, oopses or panics, and potentially abrupt host reboots or hung systems that require manual recovery. The vulnerable code path is local (requires access to a host that can manipulate configfs or NVMe‑FC ports), and there is no authoritative public evidence of remote code execution tied to this CVE as of disclosure; nevertheless, the operational impact on storage-heavy systems makes it high priority to patch.Technical anatomy — what exactly went wrong
The actors: associations, RCU list and workqueues
- nvmet‑fc represents per‑controller/per‑initiator relationships as associations stored in an RCU-protected list.
- Association teardown is performed by scheduling work items to a kernel workqueue; those work items free resources attached to the association.
- Multiple high-level routines (for example, nvmet_port_del_ctrls and nvmet_disable_port can, during a forced shutdown, each arrange for remaining associations to be scheduled for deletion.
- First routine schedules deletion work A for association X.
- Work A executes and frees the association’s resources.
- Second routine schedules deletion work B for association X — but the list entry has already been removed and freed by work A; because the lookup window is gone under RCU semantics, work B will proceed against invalid state or attempt to re-delete already freed resources.
Why RCU changes the game
RCU gives high read concurrency without locks at the cost of delayed reclamation and different lookup semantics. When a data structure is on an RCU list and an object can be freed asynchronously, the conventional pattern — "lock, lookup, remove" — is not available for callers that are not allowed to block or that operate under RCU read-side constraints. That design choice increased the risk that a second scheduler would not be able to safely re-check the list entry at scheduling time; therefore, adding a stable per‑association flag was the practical, correct fix. This is the exact engineering trade‑off the upstream commit addresses.Affected versions, upstream fixes and vendor tracking
The Linux kernel CVE team and upstream maintainers assigned CVE‑2025‑40343 and merged fixes into stable branches. Upstream commit mappings reported in public advisories show the fix merged into multiple stable series:- Fixed in 5.15.197 with commit 2f4852db87e25d4e226b25cb6f652fef9504360e.
- Fixed in 6.1.159 with commit 85e2ce1920cb511d57aae59f0df6ff85b28bf04d.
- Fixed in 6.6.117 with commit 601ed47b2363c24d948d7bac0c23abc8bd459570.
Impact and exploitability — put into operational terms
- Primary impact: Availability. Systems can crash, oops, or enter unstable states when the same deletion is scheduled twice and a handler runs against freed resources.
- Exploitability: Local. Triggering the sequence requires the ability to force a port shutdown via configfs or otherwise cause the nvmet_port_subsys_drop_link → nvmet_port_del_ctrls/nvmet_disable_port flow to execute.
- Public exploitation: At disclosure there is no authoritative public proof‑of‑concept demonstrating remote compromise or privilege escalation stemming from this CVE. That said, double-deletion / lifecycle races have historically been considered dangerous because they can produce allocator corruption that, in theory and under highly specific conditions, could be escalated — but doing so is non-trivial and typically requires additional primitives. Treat immediate remote code execution claims as unverified until reproducible PoCs appear.
Detection, hunting and forensics
Detection for this class of kernel race focuses on host-level telemetry and kernel logs:- Grep kernel logs (persistent journald or centralized syslog) for phrases and traces:
- "kernel BUG", "list_del corruption", "lib/list_debug.c"
- NVMe‑FC tokens: NVME-FC, nvme‑fc, "transport association", "io timeout"
- Workqueue / kworker backtraces that reference nvme_fc or related symbols
- Correlate with storage events:
- Preceding I/O timeouts, controller resets, or fabric events recorded in storage switch logs or SAN controllers
- If you capture a crash, preserve a vmcore / kdump image and the full dmesg output before rebooting; the backtrace will help maintainers map an incident to this specific race.
- journalctl -k | egrep -i 'nvme|nvme-fc|list_del|lib/list_debug'
- dmesg | egrep -i 'io timeout|transport association|nvme-fc'
- lsmod | grep nvme
- modinfo nvme-fc
Remediation and mitigation — practical playbook
The single, reliable remediation is to run a kernel that includes the upstream fix (or a vendor backport) that implements the association‑terminating flag and prior-check before scheduling deletion. Because kernel updates require reboots, remediation is a two-step process (install packages, then reboot).Operational playbook (ordered):
- Inventory: Identify hosts that load nvme‑fc or that serve NVMe‑FC devices.
- Commands: uname -r; lsmod | grep nvme; modinfo nvme-fc; check orchestration/CMDB for hosts with Fibre Channel HBAs or NVMe‑FC usage.
- Map package fix: Consult your distribution or OEM security advisory to find the exact kernel package version that includes the upstream commit IDs (5.15.197, 6.1.159, 6.6.117 or vendor-specific backports). Do not assume shipping images are patched until verified.
- Stage and test: Apply the kernel update on a pilot group, reboot, and validate storage I/O under workloads that exercise association teardown. Use soak tests that trigger controller removal/reattach events to validate the ordering fix.
- Rollout: Schedule maintenance windows for full rollouts, prioritize high‑value storage and hypervisor hosts first.
- Monitor: After patching, keep a heightened kernel‑log monitoring window (1–2 weeks) for residual traces or regression signals; validate that prior oops patterns disappear.
- Avoid forced port shutdowns via configfs or other actions that cause mass association deletion in production.
- If the host does not require NVMe‑FC, consider blacklisting the nvme‑fc module at boot (echo "blacklist nvme-fc" > /etc/modprobe.d/blacklist-nvme-fc.conf) — but note that unloading a module while controllers are active can itself trigger races; prefer preventing module load at boot for hosts that do not use NVMe‑FC.
Verification: how to confirm a kernel contains the fix
There are three complementary approaches to verify a kernel package actually includes the upstream remediation:- Vendor advisory / package changelog: Most distributors include either the CVE number or upstream commit IDs in the kernel package changelog. Verify the vendor-supplied package lists CVE‑2025‑40343 or the upstream commit(s) before declaring a host remediated.
- Inspect the kernel source tree: If you build your own kernels or manage private kernels, inspect the relevant nvmet‑fc source file(s) and confirm the patch adding the terminating flag/guard is present (look for commit IDs listed in the upstream references).
- Smoke test: After rebooting into the patched kernel in a staging environment, run stress tests that generate association teardown events (controller removal while I/O is active) and confirm the previous list_del/list corruption traces do not recur. Keep persistent kernel logging enabled during the test.
Testing guidance for QA and SRE teams
To validate the fix safely:- Recreate environment: Use the same kernel series and HBA firmware versions as production, and configure an NVMe‑FC controller/session.
- Baseline capture: Record kernel dmesg and workload logs on unpatched hosts to capture the pre‑fix failure pattern for reference.
- Trigger the sequence: Initiate forced port shutdown via configfs or controlled controller removal while heavy I/O is running to exercise the association cleanup sequence.
- Observe kernel logs: On vulnerable kernels, you may reproduce list_del corruption or workqueue-based oops; on patched kernels, these traces should no longer appear.
- Soak tests: Run long-duration I/O tests that repeatedly attach/detach controllers or associations to ensure the ordering fix holds under sustained concurrency.
Risk analysis and critical commentary
Strengths of the upstream fix
- The patch is small and surgical: adding a terminating flag and ensuring the check runs before scheduling deletion is a low‑risk change that directly addresses the root cause (ordering), not a workaround.
- Small changes are easier to backport into stable kernel branches, which expedites distribution‑level remediation across long‑term support kernels.
Residual risks and caveats
- Kernel workqueue/RCU races are subtle. A single ordering fix closes a documented window, but other code paths may still interact unpredictably under unusual failure modes (HBAs, firmware bugs, or exotic fabrics).
- Vendor/OEM kernels and embedded images are the long tail of risk; many appliances and vendor-supplied kernels lag upstream and may not carry the upstream commit immediately — operators must verify vendor advisories rather than assuming all images are patched.
- Manual operator actions (force unloads, module removal) intended as mitigations can worsen concurrency races and should be avoided unless recommended by vendor guidance.
On severity scoring and operational priority
Different trackers assign varying severity metrics (for example, some entries list CVSS v3 around 7.1 while others rate with different vectors); severity estimates reflect tradeoffs between local attack vectors and the real-world impact on critical storage infrastructure. For WindowsForum readers and enterprise operators, treat this as an operational-availability emergency for hosts that run NVMe‑FC workloads: schedule patching quickly for production storage and hypervisor nodes.Quick checklist for administrators (one‑page playbook)
- Inventory hosts with NVMe‑FC (lsmod | grep nvme; lspci for FC HBAs).
- Check vendor advisories and map fixed package versions to your kernel series (look for CVE‑2025‑40343 or upstream commit IDs).
- Patch a test cohort with the vendor-provided kernel update and reboot.
- Run controlled association/port removal tests and monitor dmesg/journalctl for prior oops patterns.
- Roll out to production hosts in prioritized groups, re‑testing and monitoring during each stage.
- If you cannot patch immediately, avoid forced configfs port shutdowns and consider blacklisting nvme‑fc where it is not required.
Conclusion
CVE‑2025‑40343 is a classic example of a kernel lifecycle/race bug where small ordering mistakes in teardown sequencing cause outsized availability impact. The upstream remedy is concise and correct: ensure an association is marked as terminating (or otherwise guarded) before scheduling deletion work so the same association cannot be queued twice and freed twice under RCU protections. For organizations running NVMe‑FC in production, this defect deserves fast attention: inventory NVMe‑FC hosts, verify vendor kernel mappings to the upstream commits, stage and validate patched kernels under realistic I/O teardown scenarios, and then rollout patches with careful monitoring. While there is no public evidence of remote exploitation, the operational risk — kernel oops and host instability for storage-critical systems — is sufficient justification for urgent remediation and conservative operational controls until all affected hosts are patched.Source: MSRC Security Update Guide - Microsoft Security Response Center