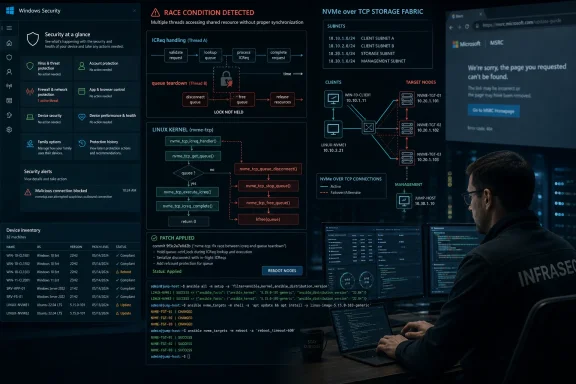
Microsoft’s Security Update Guide entry for CVE-2026-46135 points to a Linux kernel nvmet-tcp race condition fixed in April 2026, but the public MSRC page was unavailable during checks, leaving administrators to triangulate the risk from upstream kernel discussion and downstream package channels. That is not just an inconvenience. It is a reminder that modern Windows-adjacent security work increasingly depends on Linux plumbing, cloud distributions, storage fabrics, and machine-readable advisories that need to survive when the glossy front end does not.
CVE-2026-46135 is not a Windows desktop bug, and that is precisely why it matters to this audience. The vulnerable code sits in
The upstream patch describes a race between Initialization Connection Request handling and queue teardown. A host can send an ICReq and then close the connection quickly enough that the target-side teardown begins before deferred work finishes processing the already-buffered request. Under the wrong timing, state that should remain in a disconnecting path can be overwritten back into a live or failed state, reopening a teardown path that was supposed to be guarded.
That sounds narrow, and it is. But “narrow” is not the same as “unimportant.” Kernel race conditions in storage target code tend to have a practical failure mode administrators understand immediately: crashes, hangs, reference-count corruption, or other denial-of-service behavior under edge-case network timing. For an exposed storage target, the edge case is not theoretical if an attacker or malfunctioning client can repeatedly exercise the connection lifecycle.
Microsoft’s involvement comes through its broader Linux and cloud security surface. The company’s Security Update Guide has long since stopped being only a Windows patch directory. It also carries advisories for Microsoft-maintained Linux distributions and products, including Azure Linux lineage, container hosts, appliance-style workloads, and other environments where Microsoft ships or curates open-source components.
The vulnerable path begins when
That matters because the guard exists to prevent duplicate teardown. The upstream discussion describes a later socket state change re-entering teardown and issuing a second
The fix is also telling. It does not redesign NVMe/TCP. It serializes post-send state transitions with
The
That internal-network caveat should not become a lullaby. Security teams learned the hard way that “internal only” often means “reachable after the first foothold.” Storage planes are especially attractive because they sit close to data, availability, backup windows, and recovery assumptions. A denial-of-service bug in a storage target can be strategically useful even if it never becomes remote code execution.
For WindowsForum readers, the crossover point is not whether a Windows 11 laptop is directly affected. It almost certainly is not. The crossover point is whether Microsoft-curated Linux systems, Azure-hosted workloads, WSL-adjacent developer labs, hybrid infrastructure, or third-party appliances in a Windows estate include vulnerable kernel builds with
Security advisories are not marketing pages. They are production infrastructure. They feed dashboards, patch prioritization workflows, vulnerability scanners, change-control meetings, and the first 20 minutes of an incident call when everyone is asking the same three questions: are we affected, is there a fix, and how bad is it?
To Microsoft’s credit, the company has invested in machine-readable security data and has made more of its advisories available through structured channels over the years. But the user-facing experience still matters, especially for smaller shops and community operators that do not have internal tooling wrapped around every vendor API. When the page is down, the practical burden shifts back to administrators, who must reconcile upstream patches, distro advisories, and whatever their vulnerability scanner claims to know.
That burden is manageable for a single CVE. It is corrosive at scale. The more Microsoft’s security universe includes Windows, Edge, Office, Azure services, Linux distributions, firmware-adjacent packages, and open-source components, the more fragile the old mental model becomes. Patch Tuesday is no longer a single calendar event; it is a continuous translation exercise.
That still leaves a meaningful risk band. A storage target does not need to be Internet-facing to matter. A malicious tenant, compromised host, misbehaving initiator, or adversary already inside the network may be able to trigger instability if the vulnerable path is reachable. In infrastructure, denial of service is not a consolation prize; it can be the whole objective.
The phrase “race condition” also undersells operational reality. Race bugs are difficult to reproduce during normal testing because they rely on timing. They may hide in production until workload churn, network latency, teardown storms, or deliberate probing makes the timing window reliable enough. Administrators often see the symptom before they understand the cause: an unexplained kernel crash, a storage path reset, a service interruption, or a vague vendor advisory that maps to a patched kernel.
That is why the right response is neither panic nor dismissal. The right response is inventory.
The first administrative question is whether any systems are configured as NVMe/TCP targets. Initiators and targets are different roles, and this bug concerns the target implementation. A Windows machine consuming storage from somewhere else is not the same as a Linux system exporting NVMe/TCP namespaces.
The second question is whether the relevant kernel code is present and active. Some distributions build storage transports as modules; others package or enable them differently. If
The third question is vendor lineage. If the system is running a Microsoft-maintained Linux distribution, a marketplace image, an appliance image, or a vendor kernel, the upstream patch date is only the beginning. Administrators need the downstream package version that includes the fix. That is where MSRC availability, package repositories, and vendor advisories must line up cleanly.
This shift has benefits. Centralized advisory handling can make mixed estates easier to manage, especially when Microsoft is the distributor or platform owner. A security team already watching MSRC may learn about a Linux package issue without separately tracking every upstream list.
But it also creates ambiguity. A CVE on MSRC does not automatically mean “patch every Windows client.” It may mean “patch a Microsoft-supported Linux image,” “update a container host,” “rebuild a node pool,” or “confirm whether this package exists in your estate at all.” The branding compresses multiple worlds into one alert stream, and administrators have to decompress it correctly.
That decompression is now a core skill for Windows shops. The security boundary of a Microsoft environment includes Entra ID, Defender, Azure, Linux workloads, GitHub-hosted pipelines, container registries, firmware, and third-party storage systems. The Windows admin who can read a Linux kernel advisory is no longer being extra; they are reading the room.
Storage outages cascade. Virtual machines pause. Databases stall. Backup jobs fail. Cluster failover burns through its assumptions. Monitoring sees symptoms across multiple layers, and the root cause may look like a network blip, a flaky disk, or a kernel regression rather than a remotely triggerable race.
The
Administrators should also be careful about scanner severity alone. CVSS scores are useful triage aids, but they rarely capture local topology. A medium-severity storage target crash on a critical backup network may deserve faster treatment than a higher-scored bug in an unreachable optional component.
Teams without that map end up doing security by keyword. They see “Microsoft,” assume Windows. They see “Linux kernel,” assume not their problem. They see “TCP,” assume Internet exposure. They see “storage,” forward it to another team. Each shortcut may be reasonable in isolation, but together they create delay.
This CVE is a good example of why component-level inventory is becoming more valuable than product-level inventory. “We run Azure” is not enough. “We run these kernel builds on these storage-capable Linux nodes, with these modules loaded and these ports reachable from these networks” is the kind of answer that turns a vague advisory into a change ticket.
The same logic applies to home labs and enthusiast setups. NVMe/TCP is attractive precisely because it lets tinkerers build fast networked storage from commodity gear. If that lab also hosts family services, media libraries, backups, or exposed remote access, the distinction between hobby and production gets blurry very quickly.
Network segmentation matters as well. NVMe/TCP targets should not be casually reachable from broad user networks, guest VLANs, or untrusted cloud segments. Even when patched, storage control planes deserve narrower access than general application services.
Monitoring should focus on symptoms that match the failure class. Unexpected kernel oopses, storage target resets, repeated connection churn, unexplained queue teardown messages, or crashes correlated with NVMe/TCP access deserve investigation. In a race-condition bug, logs may be sparse, but timing patterns still matter.
Change control should also avoid waiting for perfect prose from every advisory portal. If the upstream fix is clear and the downstream vendor ships a kernel update, the practical question becomes maintenance timing, not whether the web page has loaded for every analyst in the room.
 A Linux Storage Bug Lands in Microsoft’s Security Orbit
A Linux Storage Bug Lands in Microsoft’s Security Orbit
CVE-2026-46135 is not a Windows desktop bug, and that is precisely why it matters to this audience. The vulnerable code sits in nvmet-tcp, the Linux kernel’s NVMe over TCP target implementation, where storage can be exposed across an IP network using NVMe semantics rather than traditional block protocols. In plain English, this is infrastructure code: the sort of component that disappears into appliances, cloud images, lab clusters, and storage back ends until something goes wrong.The upstream patch describes a race between Initialization Connection Request handling and queue teardown. A host can send an ICReq and then close the connection quickly enough that the target-side teardown begins before deferred work finishes processing the already-buffered request. Under the wrong timing, state that should remain in a disconnecting path can be overwritten back into a live or failed state, reopening a teardown path that was supposed to be guarded.
That sounds narrow, and it is. But “narrow” is not the same as “unimportant.” Kernel race conditions in storage target code tend to have a practical failure mode administrators understand immediately: crashes, hangs, reference-count corruption, or other denial-of-service behavior under edge-case network timing. For an exposed storage target, the edge case is not theoretical if an attacker or malfunctioning client can repeatedly exercise the connection lifecycle.
Microsoft’s involvement comes through its broader Linux and cloud security surface. The company’s Security Update Guide has long since stopped being only a Windows patch directory. It also carries advisories for Microsoft-maintained Linux distributions and products, including Azure Linux lineage, container hosts, appliance-style workloads, and other environments where Microsoft ships or curates open-source components.
The Patch Tells a Clearer Story Than the Advisory Page
The interesting part of CVE-2026-46135 is that the most informative public artifact is not the advisory page. It is the upstream kernel patch discussion, where the bug is explained in terms of state transitions, locking, and reference lifetimes.The vulnerable path begins when
nvmet_tcp_handle_icreq() updates the queue state after sending an Initialization Connection Response. The patch narrative says that update was not serialized against target-side queue teardown. If teardown had already moved the queue into a disconnecting state, later ICReq processing could still rewrite the queue state and defeat the intended guard.That matters because the guard exists to prevent duplicate teardown. The upstream discussion describes a later socket state change re-entering teardown and issuing a second
kref_put() on an already released queue. In kernel terms, that is the kind of small race that can become a big reliability and security problem: a lifetime rule is violated, and what happens next depends on timing, memory reuse, and surrounding code.The fix is also telling. It does not redesign NVMe/TCP. It serializes post-send state transitions with
state_lock and bails out if teardown has already started. That is the mature shape of a kernel race fix: identify the state boundary that was being crossed without sufficient synchronization, then make the state machine harder to lie to.NVMe/TCP Is Boring Until It Becomes the Blast Radius
NVMe over TCP exists because fast storage escaped the local server. Instead of treating NVMe as only a PCIe-attached device model, data centers increasingly use NVMe semantics across Ethernet networks. That lets administrators build disaggregated storage systems without requiring specialized Fibre Channel or RDMA fabrics in every deployment.The
nvmet-tcp component is the target side of that equation. It is what makes a Linux system act as an NVMe/TCP storage target, accepting remote connections from hosts that want block storage over the network. In many environments, that function is not exposed to the public Internet, but it may be reachable inside management networks, lab fabrics, Kubernetes-adjacent storage setups, or appliance backplanes.That internal-network caveat should not become a lullaby. Security teams learned the hard way that “internal only” often means “reachable after the first foothold.” Storage planes are especially attractive because they sit close to data, availability, backup windows, and recovery assumptions. A denial-of-service bug in a storage target can be strategically useful even if it never becomes remote code execution.
For WindowsForum readers, the crossover point is not whether a Windows 11 laptop is directly affected. It almost certainly is not. The crossover point is whether Microsoft-curated Linux systems, Azure-hosted workloads, WSL-adjacent developer labs, hybrid infrastructure, or third-party appliances in a Windows estate include vulnerable kernel builds with
nvmet-tcp enabled or available.Microsoft’s Page Failure Is Part of the Story
The supplied MSRC page returned a maintenance-style failure message: servers down, try later, refresh, log back in, clear cookies, or wait a couple hours. On one level, that is mundane web ops. On another, it is exactly the wrong failure mode for a security update system that administrators increasingly treat as an operational source of truth.Security advisories are not marketing pages. They are production infrastructure. They feed dashboards, patch prioritization workflows, vulnerability scanners, change-control meetings, and the first 20 minutes of an incident call when everyone is asking the same three questions: are we affected, is there a fix, and how bad is it?
To Microsoft’s credit, the company has invested in machine-readable security data and has made more of its advisories available through structured channels over the years. But the user-facing experience still matters, especially for smaller shops and community operators that do not have internal tooling wrapped around every vendor API. When the page is down, the practical burden shifts back to administrators, who must reconcile upstream patches, distro advisories, and whatever their vulnerability scanner claims to know.
That burden is manageable for a single CVE. It is corrosive at scale. The more Microsoft’s security universe includes Windows, Edge, Office, Azure services, Linux distributions, firmware-adjacent packages, and open-source components, the more fragile the old mental model becomes. Patch Tuesday is no longer a single calendar event; it is a continuous translation exercise.
The Bug Is a Race, Not a Remote Apocalypse
It is worth resisting the temptation to inflate this into a universal emergency. The available technical description points to a race in NVMe/TCP target queue handling, not a wormable Windows flaw, not a browser zero-day, and not a broadly exposed consumer endpoint. Exploitability depends on whether the vulnerable code is present, built, loaded, configured, and reachable by an attacker capable of manipulating the connection timing.That still leaves a meaningful risk band. A storage target does not need to be Internet-facing to matter. A malicious tenant, compromised host, misbehaving initiator, or adversary already inside the network may be able to trigger instability if the vulnerable path is reachable. In infrastructure, denial of service is not a consolation prize; it can be the whole objective.
The phrase “race condition” also undersells operational reality. Race bugs are difficult to reproduce during normal testing because they rely on timing. They may hide in production until workload churn, network latency, teardown storms, or deliberate probing makes the timing window reliable enough. Administrators often see the symptom before they understand the cause: an unexplained kernel crash, a storage path reset, a service interruption, or a vague vendor advisory that maps to a patched kernel.
That is why the right response is neither panic nor dismissal. The right response is inventory.
The Practical Test Is Whether You Ship or Run nvmet-tcp
Most Windows-centric environments will not havenvmet-tcp quietly serving storage from a domain controller. But modern estates are rarely that simple. Hyper-V clusters may coexist with Linux storage nodes. Azure workloads may use Microsoft-maintained Linux images. DevOps teams may run kernel-heavy test beds that the desktop team never sees. Security teams may ingest CVEs from MSRC without realizing the affected product is not Windows itself.The first administrative question is whether any systems are configured as NVMe/TCP targets. Initiators and targets are different roles, and this bug concerns the target implementation. A Windows machine consuming storage from somewhere else is not the same as a Linux system exporting NVMe/TCP namespaces.
The second question is whether the relevant kernel code is present and active. Some distributions build storage transports as modules; others package or enable them differently. If
nvmet-tcp is not loaded and the system is not configured to serve NVMe/TCP, practical exposure is much lower. If the module is loaded on a reachable storage node, patch priority rises.The third question is vendor lineage. If the system is running a Microsoft-maintained Linux distribution, a marketplace image, an appliance image, or a vendor kernel, the upstream patch date is only the beginning. Administrators need the downstream package version that includes the fix. That is where MSRC availability, package repositories, and vendor advisories must line up cleanly.
Cloud Linux Has Made Microsoft a Kernel Messenger
There was a time when a Linux kernel storage CVE appearing under Microsoft branding would have seemed odd. That time is over. Azure made Microsoft one of the world’s most important Linux operators, and its customers now expect Microsoft security communications to cover more than the NT kernel and Win32 stack.This shift has benefits. Centralized advisory handling can make mixed estates easier to manage, especially when Microsoft is the distributor or platform owner. A security team already watching MSRC may learn about a Linux package issue without separately tracking every upstream list.
But it also creates ambiguity. A CVE on MSRC does not automatically mean “patch every Windows client.” It may mean “patch a Microsoft-supported Linux image,” “update a container host,” “rebuild a node pool,” or “confirm whether this package exists in your estate at all.” The branding compresses multiple worlds into one alert stream, and administrators have to decompress it correctly.
That decompression is now a core skill for Windows shops. The security boundary of a Microsoft environment includes Entra ID, Defender, Azure, Linux workloads, GitHub-hosted pipelines, container registries, firmware, and third-party storage systems. The Windows admin who can read a Linux kernel advisory is no longer being extra; they are reading the room.
Availability Bugs Deserve a Higher Seat at the Table
Security culture still tends to rank confidentiality and code execution above availability. That hierarchy makes sense in many threat models, but it can become misleading in storage and infrastructure. If a bug lets an attacker crash or destabilize a storage target, the business impact can be severe even without data theft.Storage outages cascade. Virtual machines pause. Databases stall. Backup jobs fail. Cluster failover burns through its assumptions. Monitoring sees symptoms across multiple layers, and the root cause may look like a network blip, a flaky disk, or a kernel regression rather than a remotely triggerable race.
The
nvmet-tcp race described here sits in the connection setup and teardown path, which is exactly where resilient systems expect noise. Clients disconnect. Links flap. Initiators retry. A robust target must treat that churn as normal, not as a path into state corruption. The patch’s emphasis on serializing transitions is therefore not a mere code cleanliness issue; it is the difference between a state machine and a suggestion box.Administrators should also be careful about scanner severity alone. CVSS scores are useful triage aids, but they rarely capture local topology. A medium-severity storage target crash on a critical backup network may deserve faster treatment than a higher-scored bug in an unreachable optional component.
The Advisory Gap Rewards Teams With Better Internal Maps
When the public advisory page is unavailable or thin, organizations with accurate asset maps win. They know which systems run Linux kernels from which vendors. They know which machines expose storage services. They know whethernvmet-tcp exists in production or only in a lab. They can make a decision before the vendor portal finishes having a bad day.Teams without that map end up doing security by keyword. They see “Microsoft,” assume Windows. They see “Linux kernel,” assume not their problem. They see “TCP,” assume Internet exposure. They see “storage,” forward it to another team. Each shortcut may be reasonable in isolation, but together they create delay.
This CVE is a good example of why component-level inventory is becoming more valuable than product-level inventory. “We run Azure” is not enough. “We run these kernel builds on these storage-capable Linux nodes, with these modules loaded and these ports reachable from these networks” is the kind of answer that turns a vague advisory into a change ticket.
The same logic applies to home labs and enthusiast setups. NVMe/TCP is attractive precisely because it lets tinkerers build fast networked storage from commodity gear. If that lab also hosts family services, media libraries, backups, or exposed remote access, the distinction between hobby and production gets blurry very quickly.
The Work Starts Before the Portal Comes Back
The sensible response to CVE-2026-46135 is straightforward but not automatic. Administrators should identify Linux systems acting as NVMe/TCP targets, determine whether their kernels include the affectednvmet-tcp code path, and apply vendor-provided kernel updates once available. If a system does not need to serve NVMe/TCP, disabling or unloading the target module reduces attack surface.Network segmentation matters as well. NVMe/TCP targets should not be casually reachable from broad user networks, guest VLANs, or untrusted cloud segments. Even when patched, storage control planes deserve narrower access than general application services.
Monitoring should focus on symptoms that match the failure class. Unexpected kernel oopses, storage target resets, repeated connection churn, unexplained queue teardown messages, or crashes correlated with NVMe/TCP access deserve investigation. In a race-condition bug, logs may be sparse, but timing patterns still matter.
Change control should also avoid waiting for perfect prose from every advisory portal. If the upstream fix is clear and the downstream vendor ships a kernel update, the practical question becomes maintenance timing, not whether the web page has loaded for every analyst in the room.
The Concrete Reading of This Particular CVE
CVE-2026-46135 is easy to misread because it arrives with Microsoft branding, Linux kernel internals, and a broken advisory experience in the same package. The compact version is less dramatic but more useful.- CVE-2026-46135 concerns the Linux kernel NVMe/TCP target implementation, not ordinary Windows client networking.
- The upstream fix addresses a race where ICReq handling can conflict with queue teardown and undermine the intended disconnecting-state guard.
- The most plausible impact is availability or stability loss on systems exposing vulnerable NVMe/TCP target functionality.
- Exposure depends on whether
nvmet-tcpis present, enabled, configured as a target, and reachable by an attacker or untrusted client. - Microsoft’s advisory presence matters for Azure Linux and other Microsoft-maintained Linux surfaces, but administrators still need downstream package confirmation.
- The immediate operational move is to inventory NVMe/TCP target usage, restrict access, and apply kernel updates from the relevant vendor channel.
References
- Primary source: MSRC
Published: 2026-05-29T01:08:22-07:00
Security Update Guide - Microsoft Security Response Center
 msrc.microsoft.com
msrc.microsoft.com
- Official source: microsoft.com
MSRC - Microsoft Security Response Center
The Microsoft Security Response Center is part of the defender community and on the front line of security response evolution. For over twenty years, we have been engaged with security researchers working to protect customers and the broader ecosystem.www.microsoft.com - Related coverage: relianoid.com
CVE-2026-23112 – Null Pointer Dereference in NVMe/TCP (nvmet_tcp_build_pdu_iovec)
CVE ID: CVE-2026-23112 Component: Linux Kernel – NVMe over TCP target (nvmet-tcp) Affected function: nvmet_tcp_build_pdu_iovec() Severity: Medium / High (kernel…www.relianoid.com - Related coverage: sentinelone.com
CVE-2026-22998: Linux Kernel NVMe-TCP NULL Pointer Flaw
CVE-2026-22998 is a NULL pointer dereference flaw in Linux kernel NVMe-TCP. Learn about its impact, affected versions, and mitigation methods.www.sentinelone.com
- Related coverage: datacomm.com
- Related coverage: thewindowsupdate.com

- Related coverage: nccgroup.com
- Related coverage: deepwiki.com
MSRC API Reference | microsoft/MSRC-Microsoft-Security-Updates-API | DeepWiki
This document provides technical reference information for the Microsoft Security Response Center (MSRC) CVRF API that underlies the MsrcSecurityUpdates PowerShell module. This covers the REST API enddeepwiki.com
- Official source: github.com
"cvrf" data of JSON fomat is not found on "https://api.msrc.microsoft.com/cvrf/v3.0/cvrf/yyyy-mmm". · Issue #143 · microsoft/MSRC-Microsoft-Security-Updates-API
I have been retrieving monthly JSON format "cvrf" data via the API below by specifying "application/json" for the "Content-Type" header. However, from this month, I cannot seem to find the JSON for... github.com
github.com
- Related coverage: openpublicapis.com
Microsoft Security Response Center (MSRC) - Free Public APIs
Programmatic interfaces to engage with the Microsoft Security Response Center (MSRC)openpublicapis.com