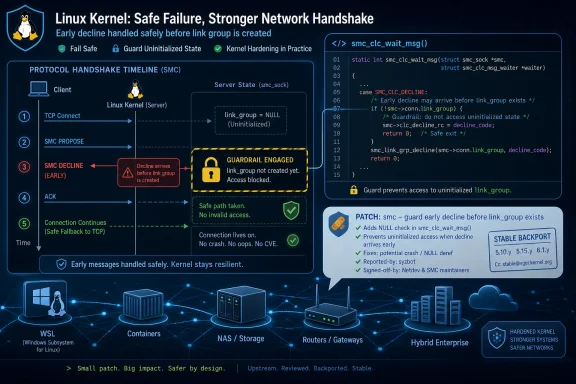
CVE-2026-46027 is a Linux kernel vulnerability published by NVD on May 27, 2026, after kernel.org reported a flaw in the SMC networking code where decline-message handling could touch link-group state before that link group existed. The fix is small, but the lesson is larger: kernel security is often decided in the awkward space between a protocol’s happy path and the failure path that arrives a few packets too early. For WindowsForum readers, this is not a “Windows bug,” but it is exactly the kind of Linux issue that matters inside WSL-adjacent workflows, virtual appliances, containers, NAS boxes, routers, and hybrid enterprise estates.
The vulnerable code sits in
The specific function named in the CVE,
The reported flaw is a classic lifetime-and-ordering problem. The code handling a CLC decline could update link-group-level synchronization state for first-contact declines, but the connection had not necessarily been associated with a link group yet. In plain English: the kernel could try to write into a room before the room had been built.
That is why the patch description is so matter-of-fact. It does not promise a sweeping redesign, and it does not describe an exploit chain. It says the code now guards the link-group update while leaving per-socket peer diagnosis behavior intact. In kernel development, that kind of sentence is often the difference between a contained bug and an avoidable crash path.
This is one of the recurring weaknesses of CVE-driven operations. Administrators are trained to sort by score, but kernel fixes often land before the scoring ecosystem has caught up. A vulnerability can be real, patched, and relevant before a scanner knows how loudly to shout about it.
The Linux kernel’s CVE process has also become more aggressive about assigning identifiers to resolved bugs, including many that are best understood as robustness and memory-safety hardening rather than cinematic remote-root events. That has irritated some operators who feel buried under low-context CVEs, but the alternative is worse. Bugs in privileged protocol parsers and state machines should not vanish into changelog fog simply because they lack a polished exploit write-up.
Here, the responsible posture is measured rather than panicked. There is no public evidence in the submitted record of active exploitation, no NVD score yet, and no indication that every Linux machine is exposed in the same way. But the affected code runs in kernel space, concerns network negotiation, and has already been fixed across stable kernel lines. That combination is enough to put it on the patch-management radar.
That matters because vulnerability impact is not only about ubiquity. A bug in a niche kernel subsystem can still matter if the subsystem is enabled in enterprise distributions, reachable through network paths, or present inside appliances whose owners do not think of themselves as “Linux kernel administrators.” Many organizations discover their Linux exposure not through servers they lovingly maintain, but through storage platforms, security tools, hypervisors, backup appliances, SD-WAN boxes, Kubernetes nodes, and vendor-managed images.
The SMC stack is also not just an application library that can crash and restart under a supervisor. It is kernel networking code. When kernel state assumptions fail, the consequences tend to be harsher: null pointer dereferences, use-after-free bugs, panics, or state corruption. The CVE text does not claim all of those outcomes here, and we should not invent them. But the class of bug is in the part of the system where conservative patching is rational.
For Windows-heavy shops, the temptation is to mentally file this under “Linux people problems.” That is increasingly obsolete. Windows estates now routinely include Linux workloads through WSL, Hyper-V guests, Azure images, container hosts, CI runners, developer workstations, network appliances, and mixed identity infrastructure. The attack surface is no longer defined by the logo on the user’s taskbar.
This is the kind of error that slips into mature code because the normal path is clean. Developers think about proposal, negotiation, resource setup, and fallback in a logical order. Networks, fuzzers, hostile peers, and broken implementations do not behave in that order. They send declines, malformed messages, disconnects, retries, and edge-case timing at the least convenient point.
The patch does what defensive kernel code should do. It keeps the per-socket diagnosis handling, because that information belongs to the socket and can remain valid. It preserves existing synchronization-error handling when a link group really exists. It only prevents link-group state from being touched when no link group has yet been established.
That distinction matters. A lazy fix might have disabled useful error reporting or changed fallback behavior broadly. A careful fix narrows the guard to the object lifetime issue. In a network stack, preserving behavior while closing an invalid access path is usually the difference between a stable backport and a regression farm.
For administrators, the actionable question is not whether the mainline kernel has the patch. It is whether the kernel you actually run has it. Enterprise Linux fleets rarely track mainline. They run vendor kernels with backported fixes, distribution-specific version strings, and security advisories that may not map cleanly to upstream numbers.
This is where patch management gets annoying. A system may report a kernel version that looks old while still containing the fix, because vendors routinely backport individual patches without rebasing to a newer upstream release. Conversely, a custom or appliance kernel may look modern enough but lag behind on a specific stable patch. Version strings are clues, not verdicts.
The practical answer is to check your distribution or vendor advisory channel, not just the upstream commit list. Ubuntu, Debian, Red Hat, SUSE, Oracle, appliance vendors, cloud image maintainers, and embedded platform suppliers all have their own cadence. If the device is important enough to route traffic, host workloads, or terminate privileged connections, it is important enough to verify the kernel fix path.
The problem is not merely bureaucratic. Many enterprise workflows treat NVD data as the canonical source for severity, affected products, CWE mappings, and scanner logic. When NVD has not enriched a record, the vulnerability can fall into a gray zone where it exists but does not yet carry the metadata that automation expects.
That gray zone is dangerous in two directions. Security teams may overreact to every kernel CVE because they lack context, creating patch fatigue and emergency maintenance for bugs that are not exposed. Or they may underreact because “N/A” looks like “not important,” even though it really means “not scored yet.”
CVE-2026-46027 is a good example of why mature programs need a middle layer between vendor advisories and raw NVD fields. The absence of a CVSS score should trigger triage, not dismissal. The triage should ask whether the vulnerable code is present, enabled, reachable, and relevant to the system’s role.
Most consumer Windows users do not need to take a special action for CVE-2026-46027. If they use Linux only through a fully managed product, normal updates are the right path. If they run WSL distributions, the more relevant kernel update path is Microsoft’s WSL kernel packaging rather than a manual upstream kernel build.
Administrators have a broader problem. They need to know where Linux kernels exist inside the Windows estate, especially in systems managed by other teams. Developer platforms, build agents, observability appliances, VPN concentrators, and security products often sit outside the traditional server patching calendar. Those are the places where “not a Windows issue” becomes “still our incident.”
The best Windows shops already treat Linux exposure as part of endpoint and infrastructure management. They inventory it, patch it, and monitor it without turning every Linux CVE into a crisis. CVE-2026-46027 fits that model: a kernel networking bug that deserves verification and routine remediation, especially where SMC is relevant or the kernel is exposed to untrusted network peers.
A decline message sounds passive. It tells the other side that the proposed mode will not be used. But inside the kernel, that message still drives code paths, updates state, records diagnostics, and influences fallback behavior. Every one of those actions is part of the protocol’s attack surface.
This is not unique to SMC. TLS alerts, SMB negotiation failures, Kerberos errors, VPN handshake rejections, Wi-Fi association failures, and HTTP/2 stream resets have all taught the same lesson in different forms. Error handling is not outside the protocol. It is the protocol under stress.
The fix for CVE-2026-46027 reflects that reality. It does not merely say “handle decline.” It says the code must distinguish between per-socket state that exists early and link-group state that exists later. That is security engineering at the object-lifetime level, where many kernel bugs are born.
But the flood also reflects a healthier truth: kernel bugs are being documented rather than buried. A small guard added to a networking path might have been a forgettable commit a decade ago. Today, it becomes a CVE, gets backported, appears in security feeds, and forces downstream vendors to account for it.
That does not mean every kernel CVE deserves the same response. Treating all of them as emergency incidents is operationally impossible. Treating all unscored CVEs as ignorable is negligent. The job is to separate exposure from mere presence.
CVE-2026-46027 appears closer to the “patch in normal expedited cadence” bucket than the “drop everything” bucket based on currently public information. The lack of a CVSS score, the specialized subsystem, and the absence of public exploitation reports argue against panic. The kernel-space location, network-handshake context, and stable backports argue against complacency.
Appliance vendors are the harder case. They often ship Linux kernels with custom patches, delayed update cycles, and limited transparency. A storage array, network appliance, industrial gateway, or security product may contain the affected code, but customers may not receive a CVE-by-CVE accounting. That makes vendor trust and support cadence part of the security boundary.
Cloud providers complicate the picture in a different way. Managed services may patch the host kernel without customer action, while customer-managed images remain the tenant’s responsibility. In hybrid environments, a single CVE can cross invisible lines between provider-managed infrastructure, customer-managed VMs, containers, and third-party appliances.
The safest operational stance is boring but effective: identify which kernels you own, which kernels your vendors own, and which ones nobody has clearly accepted responsibility for. The last category is where small kernel bugs become long-lived exposure.
A finding alone will not prove exploitability. A Linux host may include the relevant code but not use SMC. It may be shielded from untrusted peers. It may already contain a vendor backport despite an old-looking version number. Conversely, a clean scan does not guarantee the absence of the bug if the scanner lacks the right feed or cannot interpret a custom kernel.
This is why kernel vulnerability triage should include configuration and role. Is the SMC module present? Is the system using SMC-R or SMC-D? Is it a general-purpose server, a mainframe-adjacent workload, a container host, or an appliance? Is the network path trusted, semi-trusted, or hostile?
Security teams do not need to answer those questions manually for every desktop. They do need to answer them for crown-jewel infrastructure and exposed systems. The goal is not perfect certainty; it is better prioritization than “sort by CVSS,” especially when CVSS does not exist yet.
The bug was not that SMC decline handling existed. It was that a particular update belonged only after a particular association had been made. The fix respects that boundary. It allows the socket-level diagnosis to proceed while preventing premature link-group access.
That precision is important for stable kernels. Backports are safest when they change as little behavior as possible. A broad change to handshake behavior could break legitimate fallback scenarios, especially in complex enterprise deployments where SMC negotiation may interact with hardware capabilities, distribution defaults, and peer configurations.
This is also why administrators should be wary of homegrown mitigations based on vague CVE summaries. Disabling random networking features, blacklisting modules, or changing kernel parameters without understanding workload impact can create outages while failing to address the actual risk. In most environments, the correct mitigation is the patched vendor kernel.
CVE-2026-46027 is a reminder to look there. The bug itself may or may not be exploitable in a given deployment, but the process failure is familiar. Kernel updates arrive, stable patches land, vendors publish advisories, and then the systems that most need routine maintenance sit untouched because they are not in the main patching lane.
That is especially true for systems that support Windows operations without being Windows assets. Backup repositories, authentication bridges, code-signing infrastructure, CI/CD runners, and virtualization hosts are often strategically important but administratively fragmented. They are exactly where a “Linux kernel CVE” can become a Windows outage.
The right response is not to build a special program around this one CVE. It is to use it as another forcing function for inventory hygiene. If your organization cannot tell which Linux kernels it runs, who updates them, and how quickly vendor kernels are consumed, the problem is bigger than SMC.
For IT pros, the forward-looking conclusion is practical: expect more of these CVEs, not fewer. The kernel will keep turning robustness fixes into named vulnerabilities, NVD will keep lagging some of the metadata, and mixed Windows-Linux estates will keep discovering that their real attack surface crosses product boundaries. The winners will not be the teams that panic fastest; they will be the ones that can calmly identify where the code runs, whether the path is exposed, and how quickly a vendor-tested kernel can replace it.
 The Bug Lives Where Handshakes Get Messy
The Bug Lives Where Handshakes Get Messy
The vulnerable code sits in net/smc, the Linux kernel implementation of Shared Memory Communications, a protocol family designed to accelerate communication by using RDMA or related shared-memory mechanisms instead of treating every byte like a conventional TCP payload. SMC is not a household feature for desktop Linux users, but it is precisely the sort of subsystem that appears in enterprise kernels, IBM Z environments, specialized networking stacks, and performance-sensitive infrastructure.The specific function named in the CVE,
smc_clc_wait_msg(), is part of the connection-layer control handshake. During that handshake, peers negotiate whether SMC can be used and, if not, may decline and fall back to ordinary TCP behavior. That sounds harmless until the kernel’s state machine receives a decline at a point where some higher-level state has not yet been initialized.The reported flaw is a classic lifetime-and-ordering problem. The code handling a CLC decline could update link-group-level synchronization state for first-contact declines, but the connection had not necessarily been associated with a link group yet. In plain English: the kernel could try to write into a room before the room had been built.
That is why the patch description is so matter-of-fact. It does not promise a sweeping redesign, and it does not describe an exploit chain. It says the code now guards the link-group update while leaving per-socket peer diagnosis behavior intact. In kernel development, that kind of sentence is often the difference between a contained bug and an avoidable crash path.
A Low-Drama CVE Can Still Be a Real Security Signal
CVE-2026-46027 arrived with NVD enrichment still pending, no NVD CVSS score, and no published NIST severity rating. That absence is not the same thing as safety. It means the public vulnerability machinery has not yet assigned the shorthand that many dashboards use to decide whether something becomes a ticket, an exception, or an ignored row in a spreadsheet.This is one of the recurring weaknesses of CVE-driven operations. Administrators are trained to sort by score, but kernel fixes often land before the scoring ecosystem has caught up. A vulnerability can be real, patched, and relevant before a scanner knows how loudly to shout about it.
The Linux kernel’s CVE process has also become more aggressive about assigning identifiers to resolved bugs, including many that are best understood as robustness and memory-safety hardening rather than cinematic remote-root events. That has irritated some operators who feel buried under low-context CVEs, but the alternative is worse. Bugs in privileged protocol parsers and state machines should not vanish into changelog fog simply because they lack a polished exploit write-up.
Here, the responsible posture is measured rather than panicked. There is no public evidence in the submitted record of active exploitation, no NVD score yet, and no indication that every Linux machine is exposed in the same way. But the affected code runs in kernel space, concerns network negotiation, and has already been fixed across stable kernel lines. That combination is enough to put it on the patch-management radar.
SMC Is Niche Until It Is in Your Kernel
Shared Memory Communications is one of those features that reveals the split personality of Linux. On a laptop, it may be invisible. In the environments it was built for, it is a performance feature tied to serious workloads, specialized hardware, and high-value systems.That matters because vulnerability impact is not only about ubiquity. A bug in a niche kernel subsystem can still matter if the subsystem is enabled in enterprise distributions, reachable through network paths, or present inside appliances whose owners do not think of themselves as “Linux kernel administrators.” Many organizations discover their Linux exposure not through servers they lovingly maintain, but through storage platforms, security tools, hypervisors, backup appliances, SD-WAN boxes, Kubernetes nodes, and vendor-managed images.
The SMC stack is also not just an application library that can crash and restart under a supervisor. It is kernel networking code. When kernel state assumptions fail, the consequences tend to be harsher: null pointer dereferences, use-after-free bugs, panics, or state corruption. The CVE text does not claim all of those outcomes here, and we should not invent them. But the class of bug is in the part of the system where conservative patching is rational.
For Windows-heavy shops, the temptation is to mentally file this under “Linux people problems.” That is increasingly obsolete. Windows estates now routinely include Linux workloads through WSL, Hyper-V guests, Azure images, container hosts, CI runners, developer workstations, network appliances, and mixed identity infrastructure. The attack surface is no longer defined by the logo on the user’s taskbar.
The Patch Says More Than the Scorecard
The most useful line in the CVE description is not the CVE ID. It is the phrase “before the connection has been associated with a link group.” That tells us the bug is about state sequencing. A peer can send a decline while the handshake is still early, and the receiver’s decline-handling path must not assume that later-stage objects exist.This is the kind of error that slips into mature code because the normal path is clean. Developers think about proposal, negotiation, resource setup, and fallback in a logical order. Networks, fuzzers, hostile peers, and broken implementations do not behave in that order. They send declines, malformed messages, disconnects, retries, and edge-case timing at the least convenient point.
The patch does what defensive kernel code should do. It keeps the per-socket diagnosis handling, because that information belongs to the socket and can remain valid. It preserves existing synchronization-error handling when a link group really exists. It only prevents link-group state from being touched when no link group has yet been established.
That distinction matters. A lazy fix might have disabled useful error reporting or changed fallback behavior broadly. A careful fix narrows the guard to the object lifetime issue. In a network stack, preserving behavior while closing an invalid access path is usually the difference between a stable backport and a regression farm.
Stable Backports Are the Real Deadline
The CVE record lists multiple kernel.org stable references, and public mailing-list traffic shows the patch moving through the netdev process before appearing in stable review streams. That is the normal kernel pipeline doing its job: fix the bug upstream, then backport it to maintained stable kernels.For administrators, the actionable question is not whether the mainline kernel has the patch. It is whether the kernel you actually run has it. Enterprise Linux fleets rarely track mainline. They run vendor kernels with backported fixes, distribution-specific version strings, and security advisories that may not map cleanly to upstream numbers.
This is where patch management gets annoying. A system may report a kernel version that looks old while still containing the fix, because vendors routinely backport individual patches without rebasing to a newer upstream release. Conversely, a custom or appliance kernel may look modern enough but lag behind on a specific stable patch. Version strings are clues, not verdicts.
The practical answer is to check your distribution or vendor advisory channel, not just the upstream commit list. Ubuntu, Debian, Red Hat, SUSE, Oracle, appliance vendors, cloud image maintainers, and embedded platform suppliers all have their own cadence. If the device is important enough to route traffic, host workloads, or terminate privileged connections, it is important enough to verify the kernel fix path.
The NVD Lag Is Becoming Part of the Risk Model
The NVD page for CVE-2026-46027 says the record is awaiting enrichment and shows no NVD CVSS score. That is not unusual. NVD enrichment delays have become a structural fact of vulnerability management, especially as more projects assign CVEs at higher volume.The problem is not merely bureaucratic. Many enterprise workflows treat NVD data as the canonical source for severity, affected products, CWE mappings, and scanner logic. When NVD has not enriched a record, the vulnerability can fall into a gray zone where it exists but does not yet carry the metadata that automation expects.
That gray zone is dangerous in two directions. Security teams may overreact to every kernel CVE because they lack context, creating patch fatigue and emergency maintenance for bugs that are not exposed. Or they may underreact because “N/A” looks like “not important,” even though it really means “not scored yet.”
CVE-2026-46027 is a good example of why mature programs need a middle layer between vendor advisories and raw NVD fields. The absence of a CVSS score should trigger triage, not dismissal. The triage should ask whether the vulnerable code is present, enabled, reachable, and relevant to the system’s role.
The Windows Angle Is Infrastructure, Not Desktop Panic
For a WindowsForum audience, the correct framing is not “your Windows PC is vulnerable.” It is that Windows environments now depend on Linux in more places than many asset inventories admit. The Linux kernel may be under the hood of a developer’s WSL workflow, a Docker Desktop backend, an Azure-hosted service, a firewall appliance, a NAS, a backup target, or a Kubernetes worker that supports Windows applications.Most consumer Windows users do not need to take a special action for CVE-2026-46027. If they use Linux only through a fully managed product, normal updates are the right path. If they run WSL distributions, the more relevant kernel update path is Microsoft’s WSL kernel packaging rather than a manual upstream kernel build.
Administrators have a broader problem. They need to know where Linux kernels exist inside the Windows estate, especially in systems managed by other teams. Developer platforms, build agents, observability appliances, VPN concentrators, and security products often sit outside the traditional server patching calendar. Those are the places where “not a Windows issue” becomes “still our incident.”
The best Windows shops already treat Linux exposure as part of endpoint and infrastructure management. They inventory it, patch it, and monitor it without turning every Linux CVE into a crisis. CVE-2026-46027 fits that model: a kernel networking bug that deserves verification and routine remediation, especially where SMC is relevant or the kernel is exposed to untrusted network peers.
Protocol Fallback Is a Security Boundary in Disguise
The most interesting part of this vulnerability is that it lives in a decline path. Security reviews often focus on successful negotiation, authenticated sessions, and data transfer. Attackers and fuzzers love the failure paths because they are less traveled and more likely to contain assumptions.A decline message sounds passive. It tells the other side that the proposed mode will not be used. But inside the kernel, that message still drives code paths, updates state, records diagnostics, and influences fallback behavior. Every one of those actions is part of the protocol’s attack surface.
This is not unique to SMC. TLS alerts, SMB negotiation failures, Kerberos errors, VPN handshake rejections, Wi-Fi association failures, and HTTP/2 stream resets have all taught the same lesson in different forms. Error handling is not outside the protocol. It is the protocol under stress.
The fix for CVE-2026-46027 reflects that reality. It does not merely say “handle decline.” It says the code must distinguish between per-socket state that exists early and link-group state that exists later. That is security engineering at the object-lifetime level, where many kernel bugs are born.
The Kernel’s CVE Flood Is Annoying but Useful
There is a legitimate complaint that kernel CVEs have become noisier. Administrators see long lists of vulnerabilities with terse descriptions, uncertain exploitability, and no immediate mapping to their distributions. The signal-to-noise ratio can feel punishing.But the flood also reflects a healthier truth: kernel bugs are being documented rather than buried. A small guard added to a networking path might have been a forgettable commit a decade ago. Today, it becomes a CVE, gets backported, appears in security feeds, and forces downstream vendors to account for it.
That does not mean every kernel CVE deserves the same response. Treating all of them as emergency incidents is operationally impossible. Treating all unscored CVEs as ignorable is negligent. The job is to separate exposure from mere presence.
CVE-2026-46027 appears closer to the “patch in normal expedited cadence” bucket than the “drop everything” bucket based on currently public information. The lack of a CVSS score, the specialized subsystem, and the absence of public exploitation reports argue against panic. The kernel-space location, network-handshake context, and stable backports argue against complacency.
Vendors Will Decide How Visible This Becomes
For many organizations, the next chapter of CVE-2026-46027 will be written not by kernel.org or NVD but by distribution vendors. If major enterprise distributions issue clear advisories, scanners will light up with cleaner mappings. If the fix is folded quietly into routine kernel updates, the CVE may remain obscure outside teams that track upstream stable closely.Appliance vendors are the harder case. They often ship Linux kernels with custom patches, delayed update cycles, and limited transparency. A storage array, network appliance, industrial gateway, or security product may contain the affected code, but customers may not receive a CVE-by-CVE accounting. That makes vendor trust and support cadence part of the security boundary.
Cloud providers complicate the picture in a different way. Managed services may patch the host kernel without customer action, while customer-managed images remain the tenant’s responsibility. In hybrid environments, a single CVE can cross invisible lines between provider-managed infrastructure, customer-managed VMs, containers, and third-party appliances.
The safest operational stance is boring but effective: identify which kernels you own, which kernels your vendors own, and which ones nobody has clearly accepted responsibility for. The last category is where small kernel bugs become long-lived exposure.
Scanner Output Will Not Tell the Whole Story
Once CVE-2026-46027 propagates through vulnerability feeds, some scanners will flag systems based on kernel package metadata. Others may miss it until NVD enrichment improves or distribution advisories are mapped. Both outcomes are predictable.A finding alone will not prove exploitability. A Linux host may include the relevant code but not use SMC. It may be shielded from untrusted peers. It may already contain a vendor backport despite an old-looking version number. Conversely, a clean scan does not guarantee the absence of the bug if the scanner lacks the right feed or cannot interpret a custom kernel.
This is why kernel vulnerability triage should include configuration and role. Is the SMC module present? Is the system using SMC-R or SMC-D? Is it a general-purpose server, a mainframe-adjacent workload, a container host, or an appliance? Is the network path trusted, semi-trusted, or hostile?
Security teams do not need to answer those questions manually for every desktop. They do need to answer them for crown-jewel infrastructure and exposed systems. The goal is not perfect certainty; it is better prioritization than “sort by CVSS,” especially when CVSS does not exist yet.
The Fix Is Small Because the Failure Was Precise
There is a tendency to underestimate patches that look small. A guard condition can feel less important than a dramatic refactor or a headline-grabbing mitigation. In kernel code, small patches are often the cleanest expression of hard-won understanding.The bug was not that SMC decline handling existed. It was that a particular update belonged only after a particular association had been made. The fix respects that boundary. It allows the socket-level diagnosis to proceed while preventing premature link-group access.
That precision is important for stable kernels. Backports are safest when they change as little behavior as possible. A broad change to handshake behavior could break legitimate fallback scenarios, especially in complex enterprise deployments where SMC negotiation may interact with hardware capabilities, distribution defaults, and peer configurations.
This is also why administrators should be wary of homegrown mitigations based on vague CVE summaries. Disabling random networking features, blacklisting modules, or changing kernel parameters without understanding workload impact can create outages while failing to address the actual risk. In most environments, the correct mitigation is the patched vendor kernel.
The Real Exposure Is in Forgotten Linux
The most vulnerable systems in many Windows-centric organizations are not the well-managed Linux servers. They are the forgotten Linux systems: the monitoring appliance nobody logs into, the build runner installed by a departed engineer, the NAS firmware waiting for a quarterly window, the lab host that became production by accident.CVE-2026-46027 is a reminder to look there. The bug itself may or may not be exploitable in a given deployment, but the process failure is familiar. Kernel updates arrive, stable patches land, vendors publish advisories, and then the systems that most need routine maintenance sit untouched because they are not in the main patching lane.
That is especially true for systems that support Windows operations without being Windows assets. Backup repositories, authentication bridges, code-signing infrastructure, CI/CD runners, and virtualization hosts are often strategically important but administratively fragmented. They are exactly where a “Linux kernel CVE” can become a Windows outage.
The right response is not to build a special program around this one CVE. It is to use it as another forcing function for inventory hygiene. If your organization cannot tell which Linux kernels it runs, who updates them, and how quickly vendor kernels are consumed, the problem is bigger than SMC.
The Kernel Patch Tells IT Where to Look Next
The immediate lesson from CVE-2026-46027 is narrow, but the operational lessons are concrete. It is a state-ordering bug in Linux SMC handshake handling, fixed upstream and moving through stable channels, with NVD scoring still absent at publication time.- Administrators should verify whether their Linux distributions or vendors have shipped the stable kernel fix rather than relying only on upstream version numbers.
- Security teams should treat the missing NVD score as an enrichment gap, not as evidence that the vulnerability has no impact.
- Windows-focused organizations should include Linux kernels in WSL, containers, appliances, hypervisors, and cloud images when assessing exposure.
- Systems using or enabling SMC deserve closer attention than generic desktops or hosts with no realistic SMC path.
- Scanner findings should be validated against vendor backports, kernel configuration, and system role before emergency maintenance is scheduled.
- Forgotten Linux appliances and infrastructure support systems are the places where routine kernel CVEs most often become persistent risk.
A Small Guardrail in a Large Attack Surface
The enduring story of CVE-2026-46027 is not that Linux SMC is suddenly dangerous or that every unscored kernel CVE deserves front-page treatment. It is that modern infrastructure depends on thousands of small state transitions that must be correct even when peers behave unexpectedly. A decline message arriving early should not be able to confuse kernel state, and now the upstream fix says it cannot take that particular path.For IT pros, the forward-looking conclusion is practical: expect more of these CVEs, not fewer. The kernel will keep turning robustness fixes into named vulnerabilities, NVD will keep lagging some of the metadata, and mixed Windows-Linux estates will keep discovering that their real attack surface crosses product boundaries. The winners will not be the teams that panic fastest; they will be the ones that can calmly identify where the code runs, whether the path is exposed, and how quickly a vendor-tested kernel can replace it.
References
- Primary source: NVD / Linux Kernel
Published: 2026-05-28T01:04:59-07:00
NVD - CVE-2026-46027
 nvd.nist.gov
nvd.nist.gov
- Security advisory: MSRC
Published: 2026-05-28T01:04:59-07:00
Original feed URL
Security Update Guide - Microsoft Security Response Center
 msrc.microsoft.com
msrc.microsoft.com
- Related coverage: opennet.ru
- Related coverage: cve.imfht.com
CVE-2026-31507: net/smc: fix double-free of smc_spd_priv when tee() duplicates splice pipe buffer - Vulnerability Platform
[HIGH 7.8] Overview In the Linux kernel's module, under the scenario of + operations, the structure is freed twice, leading to a Use-After-Free (UAF) and kernel cve.imfht.com
cve.imfht.com
- Related coverage: ci.syzbot.org
- Related coverage: mail-archive.com
- Related coverage: kernel.googlesource.com